GOTO Kazuaki Website
Speech Indexer
Speech Indexer is a Windows GUI program that simplifies the task of developing and exploring speech/video corpora with the aid of OpenAI Whisper, an automatic speech recognition system. Speech Indexer utilizes 'Whisper.cpp' created by Georgi Gerganov, which I've compiled using MinGW-w64 for it to run on the Windows platform. To learn more about Whisper and Whisper.cpp, please visit theirt respective websites: Whisper and Whisper.cpp.
System Requirements
Setup Instructions
The transcription performance depends on which model you use. The baseline model file 'ggml-base.bin' is bundled with the program, so it's ready to use once it's downloaded. Other model files can be obtained from 'Hugging Face'. Bear in mind, the larger the model file you use, the higher the recognition accuracy, but the processing time will increase accordingly. Please store any model files you download on the 'models' subfolder of the 'Whisper.cpp' folder.
Uninstallation Instructions
Simply delete the 'SpeechIndexer' folder completely. Rest assured that the program makes no modifications to your system's registry.
Supported Media Formats
Audio Formats: WAV, MP3, M4A
Video Formats: MP4, MOV
Third-party Software
Speech Indexer makes use of the following software:
Copyright (c) 2022 OpenAI, Released under the MIT License,
see https://github.com/openai/whisper/blob/main/LICENSE
Copyright (c) 2023 Georgi Gerganov, Released under the MIT License,
see https://github.com/ggerganov/whisper.cpp/blob/master/LICENSE
*Speech Indexer incorporates Whisper.cpp, with an additional feature I've implemented.
Copyright (c) 2020 Mark Heath, Released under the MIT License,
see https://github.com/naudio/NAudio/blob/master/license.txt
Copyright (c) 2009-2022 Josh Close, Released under the Apache v2.0 license,
see https://github.com/JoshClose/CsvHelper/blob/master/LICENSE.txt
Citation Guidelines
If citing, please use the following format:
・Goto, K. (2023). Speech Indexer (Version 0.1) [Computer Software]. Retrieved from: https://www.setsunan.ac.jp/~corpus/SpeechIndexer_en.htm
Usage Instructions
Speech Indexer offers two man modes: "Corpus Builder" and "Keyword Search." Users can switch between these modes by selecting the tabs in the tool bar.
How to Transcribe Files
This section shows you how to use the "Corpus Builder" mode for transcription.
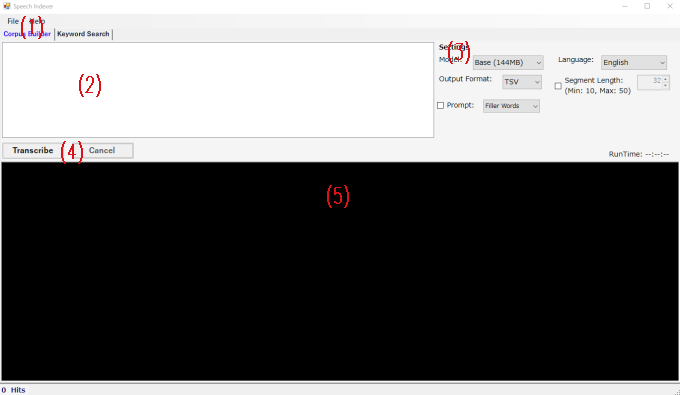
(1), (2)
Clicking on the "Files" button in the file menu (shown as (1) in the image above) will open a context menu with the following options.
(3): Transcription Settings
(4), (5)
How to Search Transcripts for Keywords
This section shows you how to use the "Keyword Search" mode.
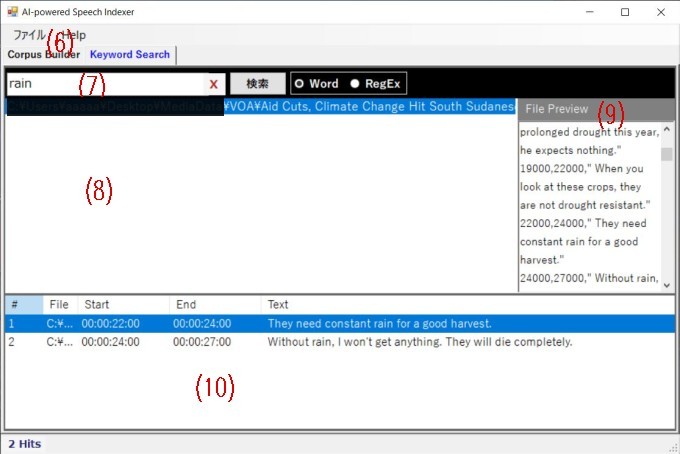
(6), (8)
Clicking on the "Files" button in the file menu (shown as (6) in the image above) will open a context menu with the following options.
(7): Enter a search string, which can be either a single word or a regular expression.
(9): You can see the preview of the file in the "Preview" area (shown as (9) in the image above) by double-clicking on it in the "Selected File" list.
(10): The table (shown as (10) in the image above) shows search results with these headings: "File Path," "Start," "End," and "Text". By double-clicking on any of these lines, the corresponding audio/video file will start playing in a separate window.
How to Navigate through Media Files
This function allows you to find how a word or phrase you search for is spoken in specific contexts.
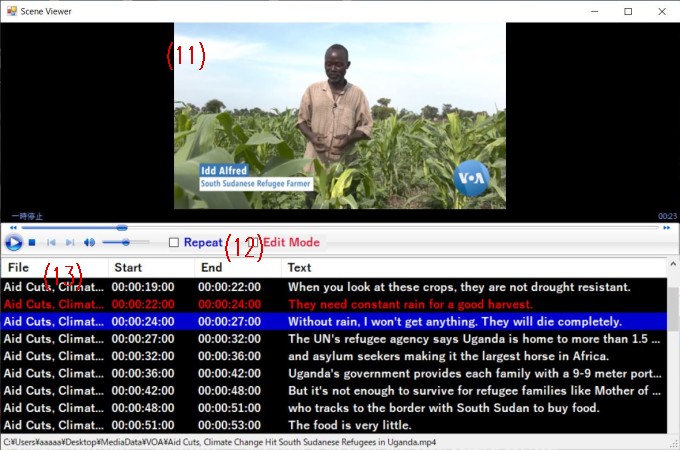
(11): Windows Media Player is displayed in "Scene Viewer" (shown as (11) in the image above) to play a media file.
(12)
Repeat: If you want the current segment to loop, tick the checkbox.
Edit Mode: Ticking the checkbox will enable you to edit the displayed file.
(13):The table (shown as (13) in the image above) shows transcription details: "File," "Start," "End," and "Text" for the current and several subsequent segments. Double-clicking on any of these segments to play the corresponding scene.
Terms of Use
These Terms of Use apply to those (hereinafter referred to as "Users") who uses the software published by Kazuaki Goto (hereinafter referred to as "the Developer") on the website.
(Freeware)
1 Speech Indexer (hereinafter referred to as "the Software") available on the Developer's website may be used free of charge, whether for personal, educational, research or commercial purposes.
(Copyright)
2 The copyright of the Software belongs to the Developer.
(Prohibited Activities)
3 Users must NOT:
(1) Monetize the Software, whether by selling or leasing it.
(2) Use the Software to violate someone's intellectual property rights or defame another person or entity.
(3) Reverse engineer, decompile, or disassemble the Software.
(4) Redistribute the Software without Developer's permission.
(5) Engage in any other act that causes damage to the Developer through the use of the Software.
(Termination of Software Provision)
4 The Developer reserves the right to terminate the provision of the software at any time. The Developer shall not be held responsible for any harm or losses experienced by Users due to this termination.
(Disclaimer)
5 The Developer accepts no liability for any harm or damages that may arise from the Software's use or non-use. Additionally, the Developer is not obligated to address or fix any issues or defects in the Software.
(Updates to Terms of Use)
6 The Developer can amend these Terms of Use without prior notice to Users. These amendments become effective when posted on the Developer's website.
Update History
Version 0.22: Dec. 2023
Version 0.21: Dec. 2023
Version 0.2: Oct. 2023
Version 0.11: Sep. 2023
Version 0.1: Sep. 2023